For AI rubric scoring to be useful in a school or district, it has to be trustworthy. That means it needs to score the way a trained evaluator would score: consistently, accurately, and in a way that reflects what your organization actually values. Without that trust, the data becomes noise and the feedback loses its credibility. This means AI’s potential to drive meaningful improvement goes unrealized.
At Swivl, we take this seriously. This post explains what we’ve done to ensure M2 scores like a trained human evaluator, and how we continue to monitor and refine that accuracy over time.
M2’s Custom Rubrics
M2 provides organizations a way to define the instructional criteria that matter most to their team. Through M2’s custom rubrics feature, organizational leaders can specify performance indicators and scoring criteria that reflect their values and expectations.
After each lesson, M2 evaluates the teaching activity against those rubrics and returns a score on a 1–4 scale, along with feedback explaining the score, highlighting strengths, and identifying areas for growth.
The promise of this feature is powerful: frequent, consistent, criteria-aligned feedback at scale, without walk-throughs or high-pressure observations. But that promise only holds if the scores are accurate.
The problem we set out to solve
Early in M2’s development, we identified a scoring distribution challenge: the system was returning scores that clustered in the middle of the scale, producing mostly 2s and 3s regardless of actual instructional quality. This is a common challenge when building AI scoring systems. The model hedges rather than discriminates, and the result is feedback that feels generic and uninformative.
We needed M2 to produce a score distribution that looked like what trained evaluators produce, which is an appropriate 1–4 spread that reflects genuine differences in instructional performance.
How we calibrated M2 against expert evaluators
To address this, we built an evaluation dataset using classroom observation videos that had already been scored by highly trained human evaluators. These were not casual reviewers, but evaluators with deep familiarity with professional teaching rubrics and established inter-rater reliability.
We then ran M2 against those same videos and compared the output.
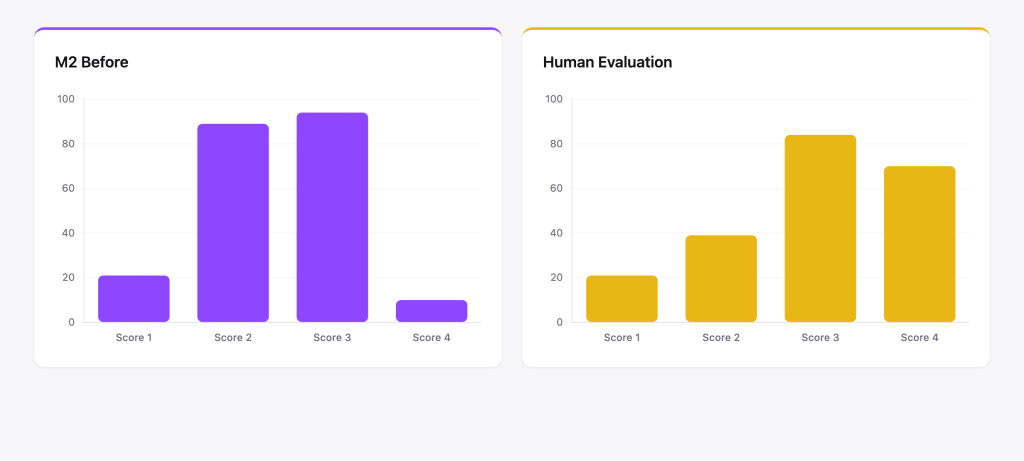
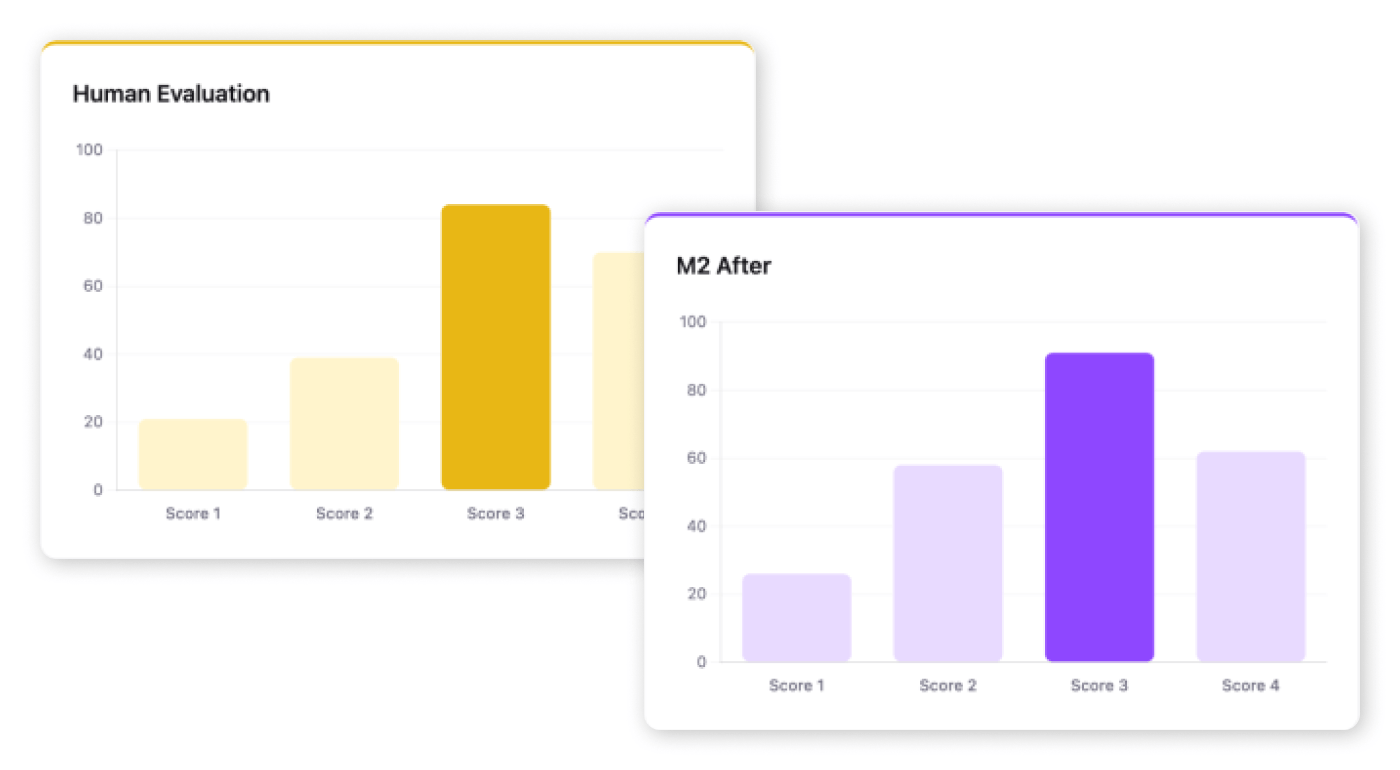
The gap between the two distributions was clear. Our human evaluators produced the kind of spread you’d expect from a well-calibrated rubric: a meaningful range of 1s, 2s, 3s, and 4s. M2’s initial output clustered near the middle.
From there, we went through an iterative calibration process: adjusting how M2 analyzes transcripts, restructuring the way rubric criteria are applied, and refining the scoring methodology at each step. Each iteration was tested against the same evaluation dataset and compared to the human baseline.
One key improvement came from how we structured M2’s rubric evaluation process. Rather than evaluating a lesson holistically, we introduced a more structured, criterion-by-criterion approach. Essentially, we gave M2 a more disciplined framework for applying each rubric dimension, similar to how a trained observer would work through an evaluation instrument item by item.
We also differentiated M2’s feedback language by score level. A score of 1 now more clearly focuses on what was missing and what the teacher can do differently. A score of 4 now emphasizes what went well and why it was effective. This mirrors how skilled coaches communicate; the message you deliver to a struggling teacher is structurally different from the message you deliver to a strong one.
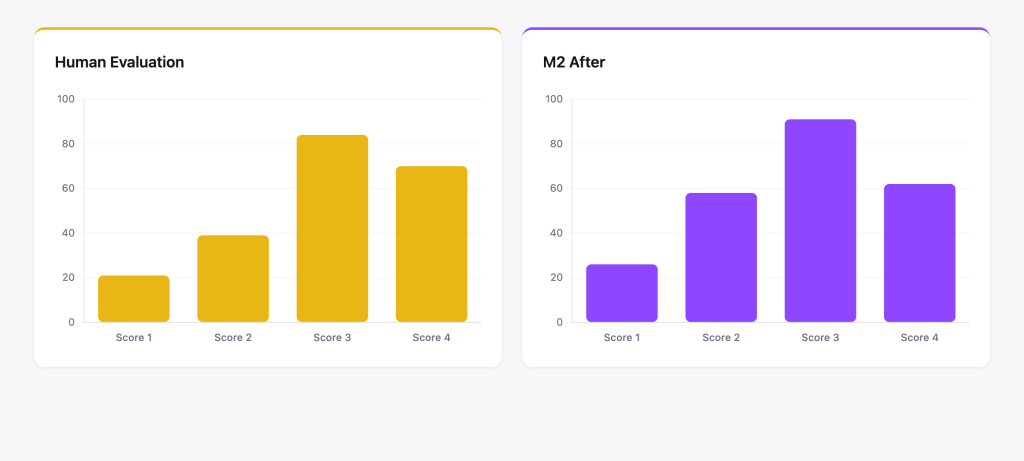
After calibration, M2’s score distributions align closely with those of our human evaluators. The gap narrowed substantially, and M2 now produces the range and differentiation that makes feedback actionable.
What the remaining differences tell us
The goal of this calibration was less about achieving a perfect match, and more about understanding where differences exist and why. There are cases where M2 and human evaluators diverge, and those cases are instructive.
Most remaining differences occur at the boundaries of rubric descriptors: situations where a teaching performance sits between a 2 and a 3, for example, and reasonable evaluators could score it either way. This is not a failure of the AI. Instead, it reflects the same ambiguity that human evaluators navigate.
In fact, inter-rater reliability among trained human evaluators on rubric items like these is rarely 100%, and M2’s agreement rate with our evaluators compares favorably to the agreement rate between two independent human scorers on the same material.
For now, one unique capability of human evaluators is eyesight. M2 currently relies on class transcripts for the analysis that leads to scores and feedback. However, we are investigating the safe, privacy-centric approach to bringing visual evaluation capabilities to M2 in upcoming releases.
Understanding boundary cases and the work process of AI vs. humans helps us continue to define clear paths for improvement.
Ongoing monitoring and refinement
Calibration is not a one-time event. As M2 is deployed across diverse classrooms, grade levels, and instructional contexts, we continue to monitor scoring accuracy and precision.
We define accuracy as how closely M2’s scores align with a trained human evaluator. We define precision as how consistent M2’s scoring is across similar lessons. In other words, whether it gives comparable scores when evaluating comparable teaching. Both accuracy and precision matter.
Our team runs ongoing comparisons between M2 output and human-evaluated samples, identifying drift and opportunities to improve. When we find systematic gaps, we refine our approach and re-validate. This continuous loop is what allows M2’s scoring to remain trustworthy over time, not just at the point of initial release.
The result: consistent, trustworthy feedback
When an organization deploys M2 with custom rubrics, they are not getting a black-box AI generating arbitrary scores. They are getting a scoring system that has been explicitly calibrated to match how trained evaluators apply rubric criteria — and that is continuously monitored to stay that way.
This is what makes M2’s frequent feedback valuable. Not just that teachers receive more of it, but that the feedback they receive is grounded in the same framework a skilled evaluator would apply. The score of 3 a teacher receives on Monday should mean the same thing as the score of 3 they receive two weeks later, because M2 applies its criteria consistently.
When teachers and leaders can trust the scores, they can use them. Coaching conversations become more specific. Professional development becomes more targeted. And leaders gain a reliable, ongoing view of where their organization is performing and where it needs to grow — without the cost and inconsistency of traditional evaluation systems.
M2’s AI rubric scoring is built to earn that trust. And we’ve done the work to prove it.